이 강의 URL은 다음과 같습니다(북마크 추가!): https://www.codeonweb.com/@mookiekim/ml-glossary
CodeOnWeb 꿀팁1
우측 하단의 목차 아이콘을 사용하시면 원하는 용어를 더욱 쉽고 빠르게 찾을 수 있습니다. 목차는 목차 아이콘을 한번 더 누르면 사라집니다.
CodeOnWeb 꿀팁2
목차에서 클릭하면 나타나는 해당 용어의 링크를 통해 외부에서 바로 접근할 수 있습니다. 이런 식으로요: https://www.codeonweb.com/@mookiekim/ml-glossary#machine-learning
가중치 weight
선형 모델의 특징 혹은 심층 신경망의 변의 계수. 선형 모델을 훈련하는 목적은 각 특징의 이상적인 가중치를 알아내기 위함. 가중치가 0이라면, 해당 특징은 모델에 기여하지 않음.
거짓 양성 false positive (FP)
모델이 양성 범주로 잘못 예측한 보기. 예를 들어, 모델이 특정 이메일이 스팸이라고 추론했으나(양성 범주), 실제로는 스팸이 아니었던 경우.
거짓 양성률 false positive rate (FP rate)
ROC 커브의 X축. 거짓 양성률은 다음과 같이 정의됨:
거짓 음성 false negative (FN)
모델이 음성 범주로 잘못 예측한 보기. 예를 들어, 모델이 특정 이메일이 스팸이 아니라고 추론했으나(음성 범주), 실제로는 스팸이었던 경우.
검증 세트 validation set
하이퍼파라미터의 조정을 위해 훈련 세트에서 분리한 데이터셋의 부분 세트.
결정 경계 decision boundary
이진 분류 혹은 다중범주 분류 문제 모델에서 학습된 범주 사이의 분리자. 예를 들어, 이진 분류 문제를 표현하고 있는 다음 그림에서, 결정 경계는 오렌지색 범주와 파란색 범주의 경계임:

경첩 손실 hinge loss
각 훈련 보기와 가능한 한 떨어진 결정 경계를 찾아서 보기와 경계 간의 거리를 최대화해주는, 분류에 쓰이는 손실 함수의 한 부류. KSVMs은 경첩 손실(혹은 제곱 경첩 손실과 같은 관련 함수)을 사용함. 이진 분류에 대해 경첩 손실 함수는 다음과 같이 정의됨:
여기서 y는 -1 혹은 +1인 실제 레이블이며 y'는 다음과 같은 분류 모델의 원래 출력:
따라서, 경첩 손실 vs. (y * y')는 다음과 같이 보임:

경험적 위험 최소화 empirical risk minimization (ERM)
훈련 세트 상에서 손실을 최소화하는 모델 함수 선택. 구조적 위험 최소화와 대조해 볼 것.
계층 layer
입력 특징의 집합이나 다른 뉴런들의 출력을 처리하는 신경망 내의 뉴런의 집합.
또한, 텐서플로우 내의 추상화. 계층은 텐서와 구성 옵션을 입력으로 받아 다른 텐서를 출력으로 내보내는 파이썬 함수임. 필요한 텐서가 한번 구성되면 사용자는 모델 함수를 통해 그 결과물을 Estimator로 변환할 수 있음.
Layer의 번역에 관하여
Layer는 기계학습 용어 전체에서 가장 많이 쓰이는 용어 중 하나입니다. 여기서는 가독성과 통용되는 표현을 존중하여 단독으로 쓰일 때는 '계층'으로, 합성 명사로 쓰일 때는 '-층'으로 번역하도록 하겠습니다.
계층 API Layers API (tf.layers)
계층을 구성하는 일부로서 심층 신경망을 생성하는 텐서플로우 API. 계층 API는 다음과 같이 서로 다른 유형의 계층을 쌓을 수 있도록 함:
tf.layers.Dense: 완전연결층tf.layers.Conv2D: 합성곱층.
사용자 지정 Estimator를 작성할 때, 모든 은닉층의 특징을 정의하여 계층 객체를 구성할 수 있음.
계층 API는 Keras의 계층 API 컨벤션을 따름. 즉, 서로 다른 접두어를 제외하고는 계층 API의 모든 함수는 Keras 계층 API와 동일한 이름과 시그니처를 가짐.
공간적 풀링 spatial pooling
풀링을 참조.
과적합 overfitting
훈련 세트에 너무 가깝게 맞춰져서 새로운 데이터에 대해 옳은 예측을 해내는 데에 실패하는 모델을 만드는 것.
교정층 calibration layer
일반적으로는 예측 편향을 고려하는 예측 후 조정. 조정된 예측과 확률은 확인된 레이블 세트의 분포와 일치해야 함.
구조적 위험 최소화 structural risk minimization (SRM)
다음 두 가지 목표의 균형을 위한 알고리즘:
- 가장 예측력이 높은 모델을 만들기(예를 들어, 최소 손실).
- 가능한 한 단순하게 모델을 유지하기(예를 들어, 강력한 정규화).
예를 들어, 훈련 세트에 대해서 손실을 최소화하며 정규화하는 모델 함수는 구조적 위험 최소화 알고리즘임.
추가 정보는 http://www.svms.org/srm/를 참조할 것.
경험적 위험 최소화와 대조해 볼 것.
구획 전략 partitioning strategy
parameter servers에 걸쳐 변수를 어떻게 나눌지에 대한 알고리즘.
군집화 clustering
비지도 학습에서 관련 있는 보기들 간의 그룹화. 모든 보기들이 묶여지게 되면, 사람이 선택적으로 각 군집에 의미를 부여할 수 있음.
다양한 군집화 알고리즘이 존재하며, 예를 들어 k-means 알고리즘은 다음 다이어그램과 같이 중심점에 대한 근접도에 근거하여 군집화함:

이제 사람 연구자는 군집화 결과를 검토하여, 군집 1은 "난쟁이 나무", 군집 2는 "완전히 큰 나무"와 같이 레이블을 붙일 수 있음.
다른 예로는 다음 삽화와 같이 하나의 중심점으로부터 각 보기까지의 거리에 기반한 군집화 알고리즘도 생각할 수 있음:

그래프 graph
텐서플로우의 계산 명세. 그래프의 노드는 연산을 표현함. 모서리는 방향이 있으며, 연산의 결과(텐서)를 다른 연산의 피연산자로 넘겨주는 것을 표현함. 텐서보드를 사용하여 그래프를 시각화할 수 있음.
기계 학습 machine learning
입력 데이터로부터 예측 모델을 만드는(훈련시키는) 프로그램 혹은 시스템. 이 시스템은 학습된 모델을 사용하여 모델을 학습에 사용한 것과 동일한 분포에서 얻은 새로운(전에 본 적 없는) 데이터에 대한 유용한 예측을 만듦. 기계 학습은 이러한 프로그램이나 시스템을 다루는 연구 분야를 가리키기도 함.
기울기 gradient
모든 독립 변수에 대한 편도함수의 벡터. 기계 학습에서, 기울기는 모델 함수의 편도함수의 벡터임. 기울기는 가장 가파른 상승 방향을 가리킴.
기울기 다듬기 gradient clipping
기울기 값을 적용하기 전에 한도를 부과하는 것. 기울기 다듬기는 수치적 안정성을 보장하고 기울기 폭발을 방지하는 것을 도와줌.
기울기 하강 gradient descent
훈련 데이터에 맞춰 모델 파라미터 손실의 기울기를 계산하여 손실을 최소화하는 기법. 쉽게 말하면, 기울기 하강을 반복 수행하여 파라미터를 조절함으로써 점차로 손실을 최소화하는 최적의 가중치와 편향 조합을 찾아감.
기준선 baseline
모델의 성능이 얼마나 좋은지 비교할 만한 참고가 되는 간단한 모델 혹은 휴리스틱. 기준선은 모델 개발자가 특정 문제에 대해 기대하는 최소한의 성능을 정량화하는 데에 도움을 줌.
노드 node
다음과 같이 여러 가지 의미를 지니는 용어:
뉴런 neuron
일반적으로 복수의 입력 값을 받아 하나의 출력 값을 생성하는 신경망의 노드. 뉴런은 입력 값의 가중 합에 활성화 함수(비선형 변환)를 적용하여 출력 값을 계산함.
다중범주 분류 multi-class classification
두 개를 초과하는 범주로 분류하는 분류 문제. 예를 들어, 단풍 나무는 종이 대략 128개가 있으므로, 단풍 나무를 종 별로 분류하는 모델은 다중 범주임. 반대로, 이메일을 딱 두 개의 범주(스팸과 스팸 아님)로 나누는 모델은 이진 분류 모델임.
다항 분류 multinomial classification
다중범주 분류와 동의어.
단계 step
한 배치에 대한 정방향과 역방향 평가.
단계 크기 step size
학습률의 동의어.
독립 동일 분포 independently and identically distributed (i.i.d)
각 값이 앞에서 가져온 값에 의존하지 않으면서 값이 변하지는 않는 분포에서 가져온 데이터. i.i.d.는 기계 학습의 이상 기체와 같아서 수학적으로 유용한 구조이지만 실제로는 거의 발견되지 않음. 예를 들어, 짧은 시간 동안 만을 두고 보면 웹 페이지 방문자의 분포는 i.i.d.일 수 있음; 즉, 짧은 시간을 두고 보면 분포가 바뀌지 않으며 한 방문자의 방문은 일반적으로 다른 방문자에 대해 의존하지 않음. 하지만, 시간을 늘려보면 웹 페이지 방문자의 계절적 차이가 나타날 수 있음.
데이터 분석 data analysis
샘플, 측정, 시각화 등을 고려하여 데이터에 대한 이해를 얻음. 데이터 분석은 첫 번째 모델을 만들기 전, 데이터셋이 처음 주어졌을 때 특별히 유용함. 또한 시스템에 대한 실험을 이해하고 시스템에 대해 디버깅을 할 때도 중요함.
데이터셋 data set
보기의 모음.
데이터셋 API Dataset API (tf.data)
데이터를 읽고 기계학습 알고리즘이 요구하는 형식으로 변형해 주는 고수준 텐서플로우 API. tf.data.Dataset 객체는 하나 이상의 텐서를 포함하는 요소의 시퀀스를 표현함. tf.data.Iterator 객체는 tf.data.Dataset의 요소에 접근할 수 있도록 해줌.
상세 정보는 TensorFlow Programmer's Guide의 Importing Data를 참조.
데이터프레임 DataFrame
Pandas에서 데이터셋을 표현할 때 인기있는 데이터 타입. 데이터프레임은 표(table)를 닮음. 데이터프레임의 각 열은 이름(헤더; header)를 가지고 있고, 각 행은 숫자로 인지됨.
동적 모델 dynamic model
지속적으로 업데이트되는 방식으로 온라인 상에서 훈련된 모델. 즉, 데이터가 지속적으로 모델에 들어옴.
디바이스 device
TensorFlow 세션을 실행할 수 있는 하드웨어의 종류로, CPU, GPU, TPU를 포함함.
람다 lambda
정규화율과 동의어.
(사실, 이건 여러 의미를 지니는 용어입니다. 여기서는 정규화와 관련하여서만 얘기한 겁니다.)
랭크 rank
ML에서는 다음과 같이 여러 의미를 지님:
- 텐서의 차원의 갯수. 예를 들어, 스칼라의 랭크는 0, 벡터의 랭크는 1, 행렬의 랭크는 2.
- 범주를 높은 것 부터 낮은 것 순으로 분류하는 ML 문제에서 범주의 서수적 위치(순위). 예를 들어, 행동에 랭크를 부여하는 시스템은 개에게 줄 보상을 높은 것(스테이크)부터 낮은 것(시든 상추)까지 랭크를 부여할 수 있음.
레이블 label
지도 학습에서 보기의 "정답" 혹은 "결과" 부분. 레이블된 데이터셋의 각 보기는 하나 이상의 특징과 하나의 레이블로 구성됨. 예를 들어, 주택 데이터셋에서 특징은 침실의 갯수, 욕실의 갯수, 주택의 연식을 포함하는 한편, 레이블은 주택의 가격이 됨. 스팸 감지 데이터셋의 경우, 특징은 제목, 발신인, 이메일 자체를 포함하는 한편, 레이블은 "스팸" 혹은 "스팸 아님"이 됨.
레이블되지 않은 보기 unlabeled example
특징은 포함하지만 레이블이 없는 보기. 레이블되지 않은 보기는 추론의 입력임. 준지도 학습과 비지도 학습에서는 훈련 중에 레이블되지 않은 보기가 사용됨.
레이블된 보기 labeled example
특징과 레이블을 포함하는 보기. 지도 학습에서 모델은 레이블된 보기를 통해 학습함.
로그 손실 Log Loss
로지스틱 회귀 logistic regression
분류 문제에서 시그모이드 함수를 선형 예측에 적용하여 가능한 이산 레이블의 값 각각에 대한 확률을 생성하는 모델. 로지스틱 회귀는 종종 이진 분류 문제에 쓰이지만, 다중 범주 분류 문제에도 쓰일 수 있음(이 경우, 다중 범주 로지스틱 회귀 혹은 다항 회귀로 불림).
루트 디렉토리 root directory
복수의 모델에 대해 텐서플로우 체크포인트와 이벤트 파일 하위 디텍토리를 저장하기 위해 지정한 디렉토리.
메트릭 metric
챙겨야 하는 수치. 기계 학습 시스템에서 직접적으로 최적화 할 수도 있고 아닐 수도 있음. 시스템이 최적화 하고자 하는 메트릭을 목적라고 함.
메트릭 API Metrics API (tf.metrics)
모델을 평가하기 위한 텐서플로우 API. 예를 들어, tf.metrics.accuracy는 모델의 예측이 레이블과 얼마나 자주 일치하는지 알아냄. 사용자 지정 Estimator를 작성할 때, 모델이 어떻게 평가되어야 하는지를 지정하기 위해 메트릭 API를 불러올 수 있음.
모델 model
훈련 데이터로부터 기계 학습 시스템이 학습한 것의 표현. 상당히 여러 의미를 지니는 용어이기도 한데, 다음과 같이 두 개의 관련된 의미도 가지고 있기 때문:
모델 함수 model function
기계 학습 훈련, 평가, 추론을 구현한 Estimator 내의 함수. 예를 들어, 모델 함수의 훈련 부분은 심층 신경망의 위상기하학을 정의하고 최적화기 함수를 확인하는 등의 과제를 담당함. 사전에 만들어진 Estimators를 사용하는 경우는 모델 함수가 이미 만들어져 있음을 의미하며, 사용자 정의 Estimators사용하는 경우에는 직접 모델 함수를 만들어야 함.
모델 함수 작성의 상세한 내용은 Creating Custom Estimators을 참조.
모델 훈련 model training
최고의 모델을 알아내는 과정.
모멘텀 Momentum
학습률이 현재 단계의 도함수 뿐만 아니라, 바로 앞의 단계의 도함수에도 의존하는 복잡한 기울기 하강 알고리즘. 모멘텀은 물리학의 운동량과 유사하게 시간에 따른 기울기의 기하급수적 이동 가중 평균에 대한 계산을 수반함. 모멘텀은 때때로 학습이 국소 최저값(local minima)에 갇혀 버리는 것을 방지해 줌.
목적 objective
알고리즘이 최적화하고자 하는 메트릭.
목표 target
레이블과 동의어.
반복 수행 iteration
훈련 중 모델 가중치의 업데이트. 한번의 반복 수행은 데이터 한 배치의 손실에 대한 파라미터의 기울기 계산임.
배치 batch
모델 훈련 중 한 번의 반복 수행(즉, 한 번의 기울기 업데이트)에 쓰이는 보기의 세트. 배치 크기를 함께 참조.
배치 크기 batch size
한 배치 내의 보기 갯수. 예를 들어, SGD의 배치 크기가 1인 반면, 작은 배치의 크기는 보통 10에서 100 사이임. 배치 크기는 보통 훈련과 추론 중에는 고정됨; 다만, 텐서플로우는 동적 배치 크기를 허용.
버킷팅 bucketing
(보통은 연속인)특징을 일반적으로 값의 범위로 나뉘어진 버킷(buckets) 혹은 bins라 불리는 복수의 이진 특징으로 변환하는 작업. 예를 들어, 온도를 하나의 연속 실수 특징으로 표현하는 대신에 온도의 범위로 잘게 쪼개어 이산된 bin 단위로 나눌 수 있음. 0.1도 단위로 측정된 온도 데이터는 0.0도에서 15.0도 사이의 모든 온도가 첫번째 bin에 15.1도에서 30.0도 사이의 모든 온도가 두번째 bin에, 30.1도에서 50.0도 사이의 모든 온도가 세번째 bin에 들어갈 수 있음.
범위 조절 scaling
특징의 값의 범위를 데이터셋의 다른 특징의 범위에 맞도록 조절하는 널리 쓰이는 특징 엔지니어링의 한 실례. 예를 들어, 데이터셋의 모든 실수 특징이 0부터 1 사이의 값을 가지기를 원하고, 주어진 특정 특징의 범위가 0부터 500 사이라면 해당 특징의 각 값을 500으로 나누어 범위를 조절할 수 있음.
표준화를 함께 참조.
범주 class
열거된 레이블의 목표 값 세트 중의 하나. 예를 들어, 스팸 메일을 감지하는 이진 분류 모델에서는 스팸과 스팸 아님이 두 개의 범주. 개의 품종을 분류하는 다중 범주 분류 모델의 범주는 푸들, 비글, 불독 등등.
범주 불균형 데이터셋 class-imbalanced data set
두 범주에 대한 레이블이 두드러지게 다른 빈도로 나타나는 이진 분류 문제. 예를 들어, 0.0001의 양성 레이블 보기와 0.9999의 음성 레이블 보기로 구성된 질병 데이터셋은 범주 불균형 데이터셋이나, 0.51의 한 팀이 이긴 보기와 0.49의 다른 한 팀이 이긴 보기로 구성된 축구 경기 예측기는 범주 불균형 문제가 아님.
범주형 데이터 categorical data
이산 집합으로 된 가능값을 가지는 특징. 예를 들어, 아파트, 빌라, 단독 주택, 세 개의 가능값을 가지는 주택 형태라는 범주형 특징의 경우를 생각해 보면, 주택 형태를 범주형 데이터로 표현함으로써 모델은 주택 가격에 대한 아파트, 빌라, 단독 주택 각각의 영향을 학습할 수 있음.
때때로 이산 집합 내의 값은 상호 배타적이고 주어진 보기에 대해 오직 하나의 값만이 적용 가능함. 예를 들어, 자동차 제조사 범주형 특징은 보기 당 하나의 값(도요타과 같이)만을 받아들임. 다른 경우로, 하나 이상의 값이 적용가능할 수도 있음. 자동차는 하나 이상의 색으로 칠할 수 있으므로 자동차 색상 범주형 특징은 하나의 보기에 복수의 값(빨강과 하양)을 받을 수 있음.
범주형 특징은 때때로 이산 특징으로도 불림.
수치 데이터와 대조해 볼 것.
병진 불변성 translational invariance
이미지 분류 문제에서 이미지 내에서 객체의 위치가 바뀌어도 이미지를 성공적으로 분류해내는 알고리즘의 능력. 예를 들어, 개가 프레임의 가운데에 있든 왼쪽 끝에 있든 알고리즘이 개를 인지할 수 있음을 의미함.
보기 example
데이터셋의 한 행. 하나의 보기는 한 개 이상의 특징과 가능하다면 하나의 레이블을 포함. 레이블된 보기와 레이블되지 않은 보기를 함께 참조할 것.
볼록 집합 convex set
부분 집합 안의 임의의 두 점 사이에 그어진 선이 완전히 그 부분 집합 안에 남아 있는 유클리드 공간의 부분 집합. 예를 들어, 다음 두 형태는 볼록 집합임:

대조적으로, 다음 두 형태는 볼록 집합이 아님:

볼록 최적화 convex optimization
기울기 하강과 같은 수학적 기법을 사용하여 볼록 함수의 최저점을 찾는 과정. 많은 기계학습 연구가 다양한 문제를 볼록 최적화 문제로 공식화하여 이 문제를 좀 더 효율적으로 푸는 데에 초점을 맞춰 오고 있음.
상세한 내용은 Boyd and Vandenberghe의 Convex Optimization를 참조.
볼록 함수 convex function
함수의 그래프에서 윗 부분이 볼록 집합인 함수. 원형의 볼록 함수는 영문자 U와 같은 형태를 띄고 있음. 예를 들어 다음은 모두 볼록 함수:

대조적으로, 다음 함수는 볼록이 아님. 그래프의 윗 부분이 볼록 집합이 아님에 주목할 것:

엄밀한 볼록 함수는 전역 최소점이기도 한 국소 최소점 딱 하나만을 가짐. 고전적인 U자형 함수는 엄밀한 볼록 함수임. 하지만, 일부 볼록 함수(예를 들어, 직선)는 그렇지 않음.
다음을 포함하여 널리 쓰이는 많은 손실 함수가 볼록 함수임:
기울기 하강의 많은 변형들이 엄밀한 볼록 함수의 최소점에 가까운 점을 찾을 수 있도록 보장함. 비슷하게, 확률적 기울기 하강의 많은 변형들이 엄밀한 볼록 함수의 최소점에 가까운 점을 찾을 확률이 높음(다만, 보장하지는 않음).
두 볼록 함수의 합은 (예를 들어, L2 손실 + L1 정규화)는 볼록 함수임.
심층 모델은 볼록 함수가 결코 아님. 유의할 만한 점은, 볼록 최적화를 위해 설계된 알고리즘이 최소점을 거의 찾지 못함에도 불구하고 어쨌든 심층 신경망 상에서 꽤나 잘 작동하는 경향이 있다는 점.
분류 모델 classification model
둘 이상의 분리된 범주를 구별하는 기계 학습 모델의 한 유형. 예를 들어, 자연어 처리 분류 모델은 입력 문장이 프랑스어인지, 스페인어인지 혹은 이탈리아어인지 여부를 판별함. 회귀 모델과 비교해 볼 것.
분류 임계값 classification threshold
양성 범주를 음성 범주와 구분하기 위해 적용되는 모델 예측 점수의 스칼라 기준 값. 로지스틱 회귀 결과를 이진 분류에 대응시킬 때 사용됨. 예를 들어, 주어진 이메일이 스팸일 확률을 판별하는 로지스틱 회귀 모델의 경우, 분류 임계값이 0.9라면 0.9를 초과하는 로지스틱 회귀 값은 스팸으로 분류되고 0.9 미만인 값은 스팸 아님으로 분류됨.
비용 cost
손실과 동의어.
비지도 기계 학습 unsupervised machine learning
일반적으로 레이블되지 않은 데이터셋에 대해 패턴을 찾는 모델 훈련.
가장 일반적인 비지도 기계 학습의 쓰임새는 데이터를 유사한 보기들의 그룹으로 군집화(clustering)하는 것. 예를 들어, 비지도 기계 학습 알고리즘은 음악의 다양한 속성을 바탕으로 노래를 군집화할 수 있음. 그 결과 군집은 다른 기계 학습 알고리즘의 입력으로 사용될 수 있음(예를 들어, 음악 추천 서비스 등). 군집화는 실제 레이블을 구하기 어려운 분야에서 유용하게 쓰일 수 있음. 예를 들어, 학대 방지나 사기 방지와 같은 분야에서 군집화는 사람이 데이터를 더 잘 이해하도록 도울 수 있음.
비지도 기계 학습의 다른 사례는 주성분 분석(Principal Component Analysis, PCA). 예를 들어, 주성분 분석을 수백만 개의 장바구니 내용물 데이터셋에 적용해 보면, 레몬을 포함한 장바구니에는 자주 제산제도 들어 있음을 밝혀낼 수 있음.
지도 기계 학습과 비교해 볼 것.
빽빽한 특징 dense feature
대부분의 값이 0이 아니며 일반적으로 실수 값의 텐서인 특징. 희박한 특징과 대조해 볼 것.
빽빽한 계층 dense layer
완전연결층과 동의어.
사례 instance
보기와 동의어.
사용자 지정 Estimator custom Estimator
이 기준에 맞춰 직접 작성하여 사용할 수 있는 텐서플로우 Estimator.
사전에 만들어진 Estimators와 대조해 볼 것.
사전 믿음 prior belief
데이터에 대해 훈련을 실시하기 전에 데이터에 대해 가지고 있는 생각. 예를 들어, L2 정규화는 가중치가 작고 0 주위에 정규 분포해 있을 것이라는 사전 믿음에 의존함.
사전에 만들어진 Estimator pre-made Estimator
다른 사람이 이미 만들어놓은 Estimator. 텐서플로우는 DNNClassifier, DNNRegressor와 LinearClassifier를 포함하여 몇 가지 사전에 만들어진 Estimators를 제공함. 이 지침에 따라 직접 Estimators를 만들어서 추후 사용할 수도 있음.
사전 훈련된 모델 pre-trained model
이미 훈련되어 있는 모델 혹은 (임베딩과 같은)모델의 일부분. 신경망에 사전 훈련된 임베딩을 추가하거나 사전 훈련된 임베딩에 의존하지 않고 모델 자체의 임베딩을 훈련할 수 있음.
서브샘플링 subsampling
풀링을 참조.
선형 회귀 linear regression
입력 특징의 선형 조합으로부터 연속인 값을 출력하는 회귀 모델의 한 유형.
성능 performance
다음의 의미를 지니는 과적된 용어:
- 소프트웨어 엔지니어링에서의 전통적 의미. 즉: 이 소프트웨어가 얼마나 빨리(혹은 효율적으로) 실행되는가?
- ML에서의 의미. 여기에서는 성능은 다음 질문에 대한 대답: 이 모델이 얼마나 정확한가? 즉, 모델의 예측이 얼마나 좋은가?
세션 session (tf.session)
TensorFlow 런타임의 상태를 캡슐화하고 그래프 전체 혹은 일부를 실행하는 객체. 로우 레벨 TensorFlow API를 사용할 때는 하나 혹은 복수의 tf.session 객체를 직접 인스턴스화하고 관리할 수 있음. Estimator API를 사용할 때는 Estimator가 세션 객체를 인스턴스화함.
소프트맥스 softmax
다중범주 분류 모델에서 가능한 모든 범주 각각에 대한 확률을 제공하는 함수. 확률은 다 합해서 정확히 1.0임. 예를 들어, 소프트맥스는 특정 이미지가 개일 확률이 0.9, 고양이일 확률이 0.08, 말일 확률이 0.02 임을 알아낼 수 있음(풀 소프트맥스로도 불림).
후보 샘플링과 대조해 볼 것.
손실 loss
모델의 예측이 레이블과 얼마나 차이가 나는지의 척도. 좀 더 비관적으로 말하면, 모델이 얼마나 나쁜지의 척도. 이 값을 알아내기 위해서, 모델은 손실 함수를 정의해야만 함. 예를 들어, 선형 회귀 모델은 일반적으로 손실 함수로 평균 제곱 오차를 사용하는 반면, 로지스틱 회귀 모델은 로그 손실을 사용함.
수렴 convergence
모델 훈련 중에 일정한 숫자의 반복 수행 후에 반복 수행을 더 해도 훈련 손실과 검증 손실이 아주 조금 변하거나 전혀 변하지 않는 데에 다달은 상태를 편하게 일컬음. 즉, 현재 데이터에 대한 추가적인 훈련이 모델을 더 개선하지 못 하면 모델은 수렴에 도달. 심층 학습(deep learning)에서 종종 손실 값이 최종적으로 하강하기 전에 상당 반복 수행 동안 일정하거나 거의 일정하게 유지되어서 일시적으로 수렴되었다고 잘못 느끼게 만드는 경우가 있음.
조기 중단을 함께 참조할 것.
Convex Optimization by Boyd and Vandenberghe를 함께 참조할 것.
수치 데이터 numerical data
정수 혹은 실수로 표현되는 특징. 예를 들어, 부동산 모델에서 주택의 크기를 (평방 미터 혹은 평방 피트 형태의) 수치 데이터로 표현할 수 있음. 특징을 수치 데이터로 표현한다는 것은 특징의 값이 상호 간에 그리고 잘하면 레이블과도 수학적 관계를 가진다는 것을 의미함. 예를 들어, 주택의 크기를 수치 데이터로 표현한다는 것은 200 평방 미터의 주택이 100 평방 미터의 주택보다 두 배 크다는 것을 의미함. 더 나아가, 평방 미터로 표현된 주택의 크기가 주택의 가격과 어떤 수학적 관계가 있을 수 있음을 의미함.
모든 정수 데이터가 수치 데이터로 표현되어야 하지는 않음. 예를 들어, 한국과 같은 몇몇 국가에서는 우편 번호가 정수이지만, 정수 우편 번호는 모델에서 수치 데이터로 표현되어서는 안 됨. '20000'이라는 우편번호가 '10000'이라는 우편번호의 두 배(혹은 절반)이 아니기 때문. 더 나아가, 우편 번호가 부동산 가격에 상관관계가 있기는 하지만, 우편 번호가 '20000'인 동네의 부동산 가격이 '10000'인 동네의 부동산 가격보다 두 배라고는 가정할 수 없음. 따라서 우편 번호는 수치 데이터 대신에 범주형 데이터로 표현되어야 함.
수치 특징은 때때로 연속 특징이라고도 함.
시간 데이터 temporal data
시간 상으로 다른 지점에 기록된 데이터. 예를 들어, 연중 일자별 겨울 코트 판매량 기록은 시간 데이터.
시계열 분석 time series analysis
시간 데이터를 분석하는 기계학습과 통계학의 하위 분야. 분류, 군집화, 예상(forecast), 이상 탐지 등 많은 유형의 기계학습 문제가 시계열 분석을 필요로 함. 예를 들어, 월별 판매량 기록에 기반한 향후 겨울 코트 판매 예상에 시계열 분석을 사용할 수 있음.
시그모이드 함수 sigmoid function
로지스틱 회귀 혹은 다항 회귀 출력(log odds)을 확률에 대응시켜 0부터 1사이의 값을 반환하는 함수. 시그모이드 함수 식은 다음과 같음:
여기서 σ 는 로지스틱 회귀 문제에 대해 다음과 같음:
달리 말해, 시그모이드 함수는 σ 를 0과 1 사이의 확률로 변환함.
몇몇 신경망에서 시그모이드 함수를 활성화 함수로 사용함.
시퀀스 모델 sequence model
입력이 순서 의존성을 띄는 모델. 예를 들어, 앞서 시청한 비디오를 바탕으로 다음 시청할 비디오를 예측.
시험 세트 test set
검증 세트로 모델을 초기 검사한 후, 모델을 시험하기 위해 사용하는 데이터셋의 부분 세트.
신경망 neural network
뇌의 구조에서 영감을 받아, 단순 연결 단위 혹은 비선형이 뒤따르는 뉴런으로 이루어진 계층(최소 하나는 은닉층)으로 구성된 모델.
심층 모델 deep model
복수의 은닉층을 포함하는 신경망의 한 유형. 심층 모델은 비선형 훈련 변수에 의존함.
와이드 모델과 대조해 볼 것.
앙상블 ensemble
복수의 모델에 의한 예측의 조합. 다음 중 하나 이상의 방법으로 앙상블을 만들 수 있음:
- 다른 초기화
- 다른 하이퍼파라미터
- 다른 전체 구조
심층 와이드 모델은 앙상블의 일종.
양성 범주 positive class
이진 분류에서, 두 개의 가능한 범주는 양성과 음성으로 레이블됨. 양성 결과는 시험해 보고자 하는 바를 의미함(물론, 분명히 두 개의 결과 모두를 동시에 시험해 보고 있는 것은 맞지만, 넘어갑시다). 예를 들어, 의료 검사에서 양성 범주는 "종양", 이메일 분류에서 양성 범주는 "스팸".
음성 범주와 대조해 볼 것.
역전파 backpropagation
신경망 상에서 기울기 하강을 실행하기 위한 기본 알고리즘. 우선, 각 노드의 출력 값이 정방향을 따라 계산된(그리고 캐쉬된) 다음, 각 파라미터에 대한 오차의 편도함수가 그래프의 역방향을 따라 계산됨.
연산 Operation (op)
텐서플로우 그래프의 노드. 텐서플로우에서 텐서를 생성하고 조작하고 없애는 모든 절차는 연산. 예를 들어, 행렬곱은 텐서 두 개를 입력으로 받아 텐서 하나를 출력으로 생성하는 연산.
연속 특징 continuous feature
무한한 범위의 가능한 값을 가지는 실수 특징. 이산 특징과 대조해 볼 것.
예비 데이터 holdout data
훈련 중에 의도적으로 사용되지 않는("따로 빼놓은") 보기. 검증 데이터셋과 시험 데이터셋은 예비 데이터의 보기. 예비 데이터는 훈련된 데이터 외의 데이터에 대한 모델의 일반화 능력을 평가하는 데에 도움을 줌. 예비 데이터셋에 대한 손실은 훈련 데이터셋에 대한 손실과 비교했을 때 본 적 없는 데이터셋에 대한 손실에 대해 더 나은 평가를 제공함.
예측 prediction
입력 보기에 대한 모델의 출력.
예측 편향 prediction bias
예측의 평균이 데이터셋의 레이블의 평균으로부터 얼마나 떨어져 있는지를 가리키는 값.
오프라인 추론 offline inference
일련의 예측을 생성하여 저장하고 요구에 따라 예측을 복구하여 제공하는 것. 온라인 추론과 대조해 볼 것.
온라인 추론 online inference
요구에 따라 예측을 생성함. 오프라인 추론과 대조해 볼 것.
와이드 모델 wide model
일반적으로 많은 희박한 입력 특징을 가지는 선형 모델. 이러한 모델은 출력 노드에 직접 연결된 많은 숫자의 입력을 가진 신경망의 특수한 유형이라 "와이드" 라고 일컬음. 와이드 모델은 종종 심층 모델보다 디버깅이나 점검하기가 쉬움. 와이드 모델은 은닉층을 통해 비선형성을 표현할 수 없지만, 특징 조합과 버킷팅과 같은 변환을 사용하여 다른 방식으로 비선형성을 모델링할 수 있음.
심층 모델과 대조해 볼 것.
완전연결층 fully connected layer
완전연결층은 빽빽한 계층이라고도 함.
요약 summary
텐서플로우에서 일반적으로 훈련 중 모델 메트릭을 추적하기 위해 사용되는 특정 단계에서 계산된 값 혹은 그런 값의 집합.
원-샷-러닝 one-shot learning
단 하나의 훈련 보기만으로 효과적인 분류기를 학습할 수 있도록 설계한, 물건 분류에서 자주 쓰이는 기계 학습 접근법.
퓨-샷-러닝과 대조해 볼 것.
원-핫-인코딩 one-hot encoding
다음과 같은 희박한 벡터:
- 하나의 요소가 1로 설정됨.
- 나머지 모든 요소가 0으로 설정됨.
원-핫-인코딩은 보통 유한한 세트의 가능 값을 가지는 식별자나 문자열을 표현하는 데에 사용됨. 예를 들어, 주어진 식물 데이터셋이 15,000개의 서로 다른 종을 기록하고 있고 각각 고유한 문자열 식별자로 표시된다고 할 때, 특징 엔지니어링의 일부로서 이 문자열 식별자를 크기가 15,000인 원-핫-벡터로 인코딩할 수 있음.
은닉층 hidden layer
신경망 내에서 입력층(즉, 특징)과 출력층(예측) 사이의 합성층. 신경망은 하나 이상의 은닉층을 포함함.
음성 범주 negative class
이진 분류에서 한 범주는 양성, 다른 하나는 음성이라 불림. 양성 범주는 찾고자 하는 것, 음성 범주는 나머지 모든 가능한 것들을 의미함. 예를 들어, 의료 검사에서 음성 범주는 "종양 아님". 이메일 분류기에서 음성 범주는 "스팸 아님". 양성 범주를 함께 참조할 것.
이산 특징 discrete feature
가질 수 있는 값이 유한한 특징. 예를 들어, 특징의 값이 동물, 채소, 광물 밖에 없는 특징은 이산(혹은 범주형 categorical) 특징. 연속 특징과 대조해 볼 것.
이진 분류 binary classification
상호 배타적인 두 범주 중 하나를 출력하는 분류 과제의 한 유형. 예를 들어 이메일 메시지를 평가해 "스팸" 혹은 "스팸 아님"을 출력하는 기계 학습 모델은 이진 분류기임.
일-대-다 one-vs.-all
N개의 가능한 해답이 있는 분류 문제에 있어서, 일-대-다 해답은 N개의 분리된 이진 분류기, 즉 가능한 결과 각각마다 하나씩의 이진 분류기로 구성됨. 예를 들어, 보기를 동물, 채소, 광물로 분류하는 모델의 일-대-다 해답은 다음과 같은 세 개의 분리된 이진 분류기를 제시함:
- 동물 대 동물 아님
- 채소 대 채소 아님
- 광물 대 광물 아님
일반화 generalization
훈련 중에 사용된 데이터와는 달리, 앞서 본 적이 없는 새로운 데이터에 대해 옳은 예측을 내놓는 모델의 성능.
일반화한 선형 모델 generalized linear model
푸아송 잡음 혹은 범주형 잡음과 같은 다른 유형의 잡음에 기반한 다른 유형의 모델에 대한, 가우시안 잡음에 기반한 최소 제곱 회귀 모델의 일반화. 일반화한 선형 모델의 보기는 다음과 같음:
- 로지스틱 회귀
- 다중 범주 회귀
- 최소 제곱 회귀
일반화한 선형 모델의 파라미터는 볼록 최적화를 통해 찾을 수 있음.
일반화한 선형 모델을 다음과 같은 속성을 보임:
- 최적의 최소 제곱 회귀 모델의 평균 예측은 훈련 데이터 레이블의 평균과 같음.
- 최적의 로지스틱 회귀 모델의 평균 확률 예측은 훈련 데이터 레이블의 평균과 같음.
일반화한 선형 모델의 힘은 모델의 특징에 제한됨. 심층 모델과는 달리, 일반화한 선형 모델은 "새로운 특징을 학습"할 수 없음.
임베딩 embeddings
연속값 특징처럼 표현되는 범주형 특징. 일반적으로 임베딩은 고차원 벡터를 저차원 공간으로 변형한 것. 예를 들어, 다음과 같은 두 가지 방법으로 영어 문장의 단어를 표현할 수 있음:
- 백만개의 정수 요소를 가지는 (고차원의) 희박한 벡터. 벡터의 각 셀은 하나의 분리된 영단어를 표현함; 셀의 값은 문장에서 단어가 나타난 횟수를 표현함. 하나의 영어 문장은 50 단어 이상을 포함하는 경우가 잘 없기 때문에, 벡터의 거의 모든 셀은 0. 몇 안 되는 0이 아닌 셀도 작은 값의 정수(보통은 1)이며, 이는 문장에서 해당 단어가 나타나는 횟수를 표현함.
- 0과 1 사이의 실수 값을 가지는 몇백개의 요소를 가지는 (저차원의) 빽빽한 벡터.
텐서플로우에서 임베딩은 신경망의 다른 파라미터들처럼 역전파 손실을 통해 훈련됨.
입력층 input layer
(입력 데이터를 받는)신경망의 첫번째 계층.
입력 함수 input function
텐서플로우에서 Estimator의 훈련, 평가, 예측 메소드로 입력 데이터를 반환해주는 함수. 예를 들어, 훈련 입력 함수는 훈련 세트로부터 한 배치의 특징과 레이블을 반환함.
작은 배치 mini-batch
전체 배치의 보기 중 무작위로 선택된 작은 부분 세트이며 한 번의 훈련 혹은 추론 수행에 같이 쓰이게 됨. 작은 배치의 배치 크기는 보통 10에서 1,000 사이임. 손실 계산에 있어서 전체 훈련 데이터보다 작은 배치 단위로 수행하는 것이 훨씬 효율적임.
작은 배치 확률적 기울기 하강 mini-batch stochastic gradient descent (SGD)
작은 배치를 사용하는 기울기 하강 알고리즘. 달리 말하면, 작은 배치 SGD는 훈련 데이터의 작은 부분 세트에 근거하여 기울기를 측정함. 일반적인 SGD는 크기가 1인 작은 배치를 사용함.
재현율 recall
다음 질문에 답하는 분류 모델의 메트릭: 모든 가능한 양성 레이블 중에 모델이 얼마나 많이 식별해냈는가? 즉:
전이 학습 transfer learning
한 기계 학습 과제의 정보를 다른 과제로 보내는 학습. 예를 들어, 서로 다른 과제에 대해 서로 다른 출력 노드를 가지는 심층 모델과 같이, 다중 과제 학습에서 하나의 모델은 복수의 과제를 해결할 수 있음. 전이 학습은 단순한 과제에서 얻은 정보를 복잡한 과제로 보내거나, 데이터가 많은 과제에서 얻은 정보를 데이터가 적은 과제로 보낼 수 있음.
대부분의 기계학습 과제는 하나의 과제를 해결함. 전이 학습은 복수의 과제를 해결하는 하나의 프로그램인 인공 지능으로 나아가는 걸음마라 할 수 있음.
정규화 regularization
모델의 복잡도에 대한 벌점. 정규화는 과적합을 방지하는 데에 도움을 줌. 다음과 같은 종류의 정규화가 있음:
정규화율 regularization rate
lambda로 표현되는, 정규화 함수의 상대적인 중요성을 지정하는 스칼라 값. 다음의 단순화된 손실 식은 정규화율의 영향을 보여줌:
정규화율을 올리면 과적합은 줄지만 모델의 정확도도 낮아짐.
정밀도 precision
분류 모델의 메트릭. 정밀도는 모델이 양성 범주를 옳게 예측하는 빈도를 식별함. 즉:
정상성 stationarity
데이터셋 내에서 데이터의 분포가 하나 이상의 차원에 걸쳐 일정하게 유지되는 데이터의 속성. 가장 일반적으로는, 해당 차원이 시간이라 할 때 정상성을 보이는 데이터는 시간이 흘러도 변하지 않음. 예를 들어, 정상성을 보이는 데이터는 9월부터 12월까지 변하지 않음.
정적 모델 static model
오프라인에서 훈련된 모델.
정확도 accuracy
분류 모델이 올바르게 예측한 비율. 다중범주 분류의 경우, 정확도는 다음과 같이 정의됨:
이진 분류의 경우, 정확도는 다음과 같이 정의됨:
제곱 경첩 손실 squared hinge loss
경첩 손실의 제곱. 제곱 경첩 손실은 일반 경첩 손실보다 특이값에 대해 좀 더 가혹하게 벌점을 부과함.
제곱 손실 squared loss
선형 회귀에 쓰이는 손실 함수(L2 손실로도 알려짐). 이 함수는 모델의 레이블된 보기에 대한 예측값과 레이블의 실제 값의 차이의 제곱을 계산함. 제곱을 하기 때문에, 이 손실 함수는 나쁜 예측의 영향을 증폭함. 즉, 제곱 손실은 L1 손실보다 특이값에 좀 더 강하게 반응함.
조기 중단 early stopping
훈련 손실 감소가 끝나기 전에 모델의 훈련을 마치는 것을 뜻하는 정규화의 한 방법. 검증 데이터셋에 대한 손실이 증가하기 시작한다는 것은 일반화 성능이 나빠짐을 의미하므로 조기 중단하여 훈련을 마침.
준지도 학습 semi-supervised learning
일부 훈련 보기는 레이블이 있으나 나머지 훈련 보기는 레이블이 없는 데이터에 대한 모델 훈련. 준지도 학습을 위한 기술 중 하나는 레이블되지 않은 보기에 대해 레이블을 추론하여, 추론해낸 레이블에 대해 새로운 모델을 훈련하는 방법. 준지도 학습은 레이블되지 않은 보기는 풍부하지만 레이블을 얻는 데에 비용이 많이 드는 경우에 유용함.
중심점 centroid
k-means 나 k-median 알고리즘에 의해 정해지는 군집의 중심. 예를 들어 k가 3이면 k-means 나 k-median 알고리즘은 3개의 중심점을 찾음.
지도 기계 학습 supervised machine learning
입력 데이터와 거기에 상응하는 레이블을 이용해 모델을 훈련하기. 지도 기계 학습은 학생이 한 주제에 대해 한 세트의 질문과 그에 상응하는 정답을 가지고 학습하는 것과 유사함. 질문과 해답을 대응시키는 것에 통달하고 나면, 학생은 같은 주제에 대한 새로운(전에 본 적 없는) 질문에 대답을 할 수 있음. 비지도 기계 학습과 대조해 볼 것.
참 양성 true positive (TP)
모델이 양성 범주로 옳게 예측한 보기. 예를 들어, 모델이 특정 이메일을 스팸이라고 추론했는데, 실제로 스팸인 경우.
참 양성률 true positive rate (TP rate)
재현율과 동의어. 즉:
참 양성률은 ROC 커브의 Y축임.
참 음성 true negative (TN)
모델이 음성 범주로 옳게 예측한 보기. 예를 들어, 모델이 특정 이메일을 스팸이 아니라고 추론했는데, 실제로 스팸이 아닌 경우.
체크포인트 checkpoint
특정 시점에 모델의 변수 상태를 포착하는 데이터. 체크포인트를 사용하면 복수의 세션에서 훈련을 수행할 수 있을 뿐만 아니라, 모델의 가중치를 내보낼 수도 있음. 또한 체크포인트는 에러를 지나치고 훈련을 지속할 수 있게 할 수도 있음(예를 들어, 작업 선점 job preemption). 그래프 자체는 체크포인트에 포함되지 않음에 유의할 것.
최소 제곱 회귀 least squares regression
L2 손실을 최소화하도록 훈련된 선형 회귀 모델.
최적화기 optimizer
기울기 하강 알고리즘을 구체적으로 구현한 것. 텐서플로우의 최적화기 기본 클래스는 tf.train.Optimizer. 다른 최적화기는 주어진 훈련 세트에 대한 기울기 하강의 효과를 높이기 위해 다음 중 하나 이상의 개념을 사용함:
- momentum (모멘텀)
- 업데이트 빈도 (AdaGrad = ADAptive GRADient descent; Adam = ADAptive with Momentum; RMSProp)
- 희박함/정규화 (Ftrl)
- 좀 더 복잡한 수학 (Proximal, 기타 등등)
심지어 신경망 기반 최적화기도 상상할 수 있음.
추론 inference
기계 학습에서, 종종 레이블되지 않은 보기에 훈련된 모델을 적용하여 예측하는 과정을 일컬음. 통계학에서 추론은 관찰된 데이터에 맞게 분포의 파라미터를 조절하는 과정을 일컬음(영문 위키피디아의 통계적 추론을 참조).
출력층 output layer
신경망의 "마지막" 계층. 이 계층은 답을 포함하고 있음.
큐 queue
큐 데이터 구조를 구현한 텐서플로우 연산. 보통 I/O에 사용됨.
크기 불변성 size invariance
이미지 분류 문제에서 이미지의 크기가 바뀌어도 이미지를 성공적으로 분류해 내는 알고리즘의 능력. 예를 들어, 고양이 이미지가 2M 픽셀이든 200k 픽셀이든 알고리즘이 고양이를 인지해 낼 수 있음을 의미함. 최고의 이미지 분류 알고리즘도 여전히 크기 불변성 상의 실질적 한계는 가지고 있음에 유의. 예를 들어 20 픽셀짜리 이미지로는 알고리즘(혹은 사람)이 정확하게 고양이를 분류해내지 못함.
크로스엔트로피 cross-entropy
로그 손실의 다중범주 분류 문제에 대한 일반화. 크로스엔트로피는 두 확률 분포의 차이를 정량화함. 혼잡도와 함께 참조할 것.
탈락 정규화 dropout regularization
신경망 훈련에 유용한 정규화의 한 형식. 탈락 정규화는 하나의 기울기 단계마다 고정된 갯수의 신경망 계층의 단위를 무작위로 골라 제거하는 방식으로 이뤄짐. 단위가 더 많이 탈락될수록, 정규화 강도는 더욱 세짐. 이것은 신경망을 더 작은 신경망 간의 기하급수적으로 큰 앙상블을 흉내내도록 훈련하는 것과 유사함. 완전한 설명은 Dropout: A Simple Way to Prevent Neural Networks from Overfitting을 참조.
텐서 Tensor
텐서플로우 프로그램의 기본 데이터 구조. 텐서는 N차원의(N은 매우 클 수도 있음) 데이터 구조로, 대부분 스칼라, 벡터 혹은 행렬임. 텐서의 요소는 정수, 실수 혹은 문자열 값이 될 수 있음.
텐서 랭크 Tensor rank
랭크를 참조.
텐서보드 TensorBoard
하나 이상의 텐서플로우 프로그램의 실행 중에 저장된 요약을 표시해주는 대쉬보드.
텐서 크기 Tensor size
텐서가 포함하고 있는 스칼라 값의 총 갯수. 예를 들어, [5, 10] 텐서의 크기는 50.
텐서플로우 TensorFlow
대규모의 분산된 기계 학습 플랫폼. 데이터흐름 그래프의 전체적인 계산을 지원하는 텐서플로우 스택의 기본 API 계층을 가리키는 용어이기도 함.
텐서플로우가 주로 기계 학습에 쓰이기는 하지만, 데이터흐름 그래프를 사용하는 수치 계산을 요구하는 비-기계학습 과제에도 텐서플로우를 사용할 수 있음.
텐서플로우 서빙 TensorFlow Serving
훈련된 모델을 제품으로 디플로이 하기 위한 플랫폼.
텐서플로우 플레이그라운드 TensorFlow Playground
모델(주로 신경망) 훈련에 영향을 미치는 서로 다른 하이퍼파라미터를 시각화하는 프로그램. http://playground.tensorflow.org로 가서 텐서플로우 플레이그라운드를 실험해 보시길.
텐서 형태 Tensor shape
텐서가 다양한 차원에서 포함하고 있는 요소의 갯수. 예를 들어, [5, 10] 텐서는 차원 하나의 형태는 5, 다른 차원은 10.
특이값 outliers
대부분의 다른 값으로부터 떨어져 있는 값. 기계 학습에서 다음과 같은 항목 모두가 특이값이 될 수 있음:
- 큰 절대값을 가지는 가중치.
- 상대적으로 실제 값과 차이가 크게 나는 예측 값.
- 평균으로부터 대략 3 표준 편차를 초과하는 값의 입력 데이터.
특이값은 종종 모델 훈련에 문제를 초래함.
특징 feature
예측을 생성하는 데에 쓰이는 입력 변수.
특징 명세 feature spec
tf.Example 프로토콜 버퍼로부터 특징 데이터를 추출하기 위해 필요한 정보를 설명함. 프로토콜 버퍼는 데이터의 컨테이너에 불과하기 때문에 다음 사항을 지정해주어야만 함:
- 추출할 데이터 (즉, 특징의 열쇠)
- 데이터 타입 (예를 들어, 실수 혹은 정수)
- 길이 (고정 혹은 가변)
Estimator API는 FeatureColumns의 목록으로부터 특징 명세를 생성하기 위한 기능을 제공함.
특징 엔지니어링 feature engineering
어떤 특징이 모델 훈련에 유용할 수 있는지를 알아내고, 원본 데이터를 로그 파일이나 다른 출처로부터 해당 특징으로 변환하는 전체 과정. 텐서플로우에서 특징 엔지니어링은 종종 원본 로그 파일 엔트리를 tf.Example 프로토콜 버퍼로 변환하는 것을 의미.tf.Transform을 함께 참조할 것.
특징 엔지니어링은 때때로 특징 추출(feature extraction)이라고도 함.
특징 열 Feature column (tf.feature_column)
모델이 특정한 특징을 어떻게 해석할지를 지정하는 함수. 모든 Estimator 생성자는 이런 함수에 대한 호출에 의해 반환된 출력을 모아 놓은 리스트를 파라미터로 요구함.
tf.feature_column 함수는 입력 특징의 서로 다른 표현에 대해 모델이 쉽게 실험을 할 수 있도록 함. 상세한 내용은 TensorFlow Programmers Guide의 Feature Columns chapter를 참조.
"특징 열"은 구글에 국한된 용어임. VW시스템(Yahoo/Microsoft에서 사용) 혹은 field에서는 "namespace"라 부름.
특징 조합 feature cross
개별 특징을 교차시켜(곱하거나 곱집합 Cartesian product을 취하여) 만든 합성 특징. 특징 조합은 비선형 관계를 표현할 수 있도록 도와줌.
특징 집합 feature set
기계 학습 모델을 훈련시킬 특징 그룹. 예를 들어, 우편 번호, 건물 크기, 건물 상태 등은 주택 가격을 예측하는 모델의 간단한 특징 집합이 될 수 있음.
파라미터 parameter
ML 시스템이 훈련시키는 모델의 변수. 예를 들어, 가중치는 ML 시스템이 훈련 반복 수행을 거듭해 가며 점차 학습해 나가는 파라미터 값. 하이퍼파라미터와 대조해 볼 것.
파라미터 업데이트 parameter update
훈련 중에, 보통은 한 번의 기울기 하강 반복 수행에 대해서 모델의 파라미터를 조정하는 작업.
파생 특징 derived feature
합성 특징과 동의어.
파이프라인 pipeline
기계 학습 알고리즘을 둘러싼 인프라. 파이프라인은 데이터를 모으고, 훈련 데이터 파일에 데이터를 넣고, 하나 이상의 모델을 훈련하고, 결과물로 내보내는 과정 전체를 포함.
편도함수 partial derivative
변수 중 하나를 제외한 모든 변수를 상수로 간주하는 도함수. 예를 들어, x에 대한 편도함수 f(x, y)는 x만의 함수로 간주되는(즉, y는 상수로 유지하는) f의 도함수임. x에 대한 f의 편도함수는 식의 다른 모든 변수를 무시하고 오직 x가 어떻게 변하는지에만 집중함.
편향 bias
원점으로부터의 오프셋 혹은 절편. 기계 학습 모델에서 편향(혹은 편향 항이라고 함)은 주로 b 혹은 w0 으로 사용됨. 예를 들어 다음 수식에서 편향은 b:
예측 편향과 혼동하지 않도록 주의.
평가자 rater
보기에 레이블을 부여하는 사람. 때로 "주석자"라고도 함.
평가자간 합의 inter-rater agreement
과제를 수행할 때 인간 평가자 간에 얼마나 자주 합의하는지의 척도. 평가자 간에 합의하지 않으면, 과제 지침은 개선되어야 할 수 있음. 주석자간 합의 혹은 평가자간 신뢰도라고도 함. 가장 널리 쓰이는 평가자간 합의의 척도인 Cohen's kappa를 참조.
평균 제곱근 오차 Root Mean Squared Error (RMSE)
평균 제곱 오차의 제곱근.
평균 제곱 오차 Mean Squared Error (MSE)
보기 당 평균 제곱 손실. MSE는 제곱 손실을 보기의 갯수로 나누어서 구함. 텐서플로우 플레이그라운드가 "Training loss"과 "Test loss"로 표시하는 값이 MSE임.
표준화 normalization
값을 실제의 범위에서 보통 -1에서 +1 혹은 0에서 1 사이인 표준 범위로 변환하는 과정. 예를 들어, 어떤 특징의 자연적 범위가 800에서 6,000이라 할때, 뺄셈과 나눗셈을 통해 이 값을 -1과 +1 사이로 표준화할 수 있음.
범위 조절을 함께 참조할 것.
표현 representation
데이터를 유용한 특징에 대응시키는 과정.
풀 소프트맥스 full softmax
풀링 pooling
앞선 합성곱층에서 만든 행렬을 더 작은 행렬로 축소하는 것. 풀링은 일반적으로 풀링 영역에 대한 최대값이나 평균값을 취함. 예를 들어, 다음과 같이 3x3 행렬이 있다고 하면:

합성곱 연산과 마찬가지로 풀링 연산은 행렬을 여러 조각으로 나누고 각 조각을 stride 만큼 넘어가며 연산을 수행함. 예를 들어 풀링 연산이 합성곱 행렬을 1x1 stride의 2x2 조각으로 나누며 다음의 도식처럼 4개의 풀링 연산이 발생함. 각 풀링 연산은 각 조각의 네 값 중 최대 값을 취한다고 하면:

풀링은 입력 행렬의 병진 불변성 강화해 줌.
시각화 응용을 위한 풀링은 공간적 풀링, 시계열 응용을 위한 풀링은 시간적 풀링이라고도 함. 좀 더 편하게는 풀링을 서브샘플링(subsampling)이나 다운샘플링(downsampling)이라고도 함.
퓨-샷-러닝 few-shot learning
적은 숫자의 훈련 보기만으로 효과적인 분류기를 학습할 수 있도록 설계한, 물건 분류에서 자주 쓰이는 기계 학습 접근법.
원-샷-러닝과 대조해 볼 것.
하이퍼파라미터 hyperparameter
모델 훈련을 계속해 나가는 동안 조금씩 돌려 가며 조절하는 "손잡이". 예를 들어, 학습률이 하이퍼파라미터.
파라미터와 대조해 볼 것.
하이퍼플레인 hyperplane
한 공간을 두 개의 하위 공간으로 나누는 경계. 예를 들어, 선은 2차원의 하이퍼플레인이고, 평면은 3차원의 하이퍼플레인. 좀 더 일반적으로 기계학습에서는 하이퍼플레인은 고차원 공간을 나누는 경계. Kernel Support Vector Machines은 종종 하이퍼플레인을 매우 고차원 공간에서 양성 범주를 음성 범주와 나누는 데에 사용.
학습률 learning rate
기울기 하강을 통해 모델을 하는 데에 사용되는 스칼라 값. 매 반복 수행 마다 기울기 하강 알고리즘은 기울기에 학습률을 곱함. 결과 곱셈값은 기울기 단계으로 불림.
학습률은 핵심 하이퍼파라미터임.
합성 특징 synthetic feature
입력 특징 중에는 없으나, 하나 혹은 그 이상의 입력 특징으로부터 유도된 특징. 합성 특징의 종류는 다음과 같음:
표준화나 범위 조절만으로 생성된 특징은 합성 특징으로 간주하지 않음.
합성곱 convolution
쉽게 말하자면, 수학에서 두 가지의 함수의 혼합. 기계 학습에서, 합성곱은 가중치를 훈련하기 위해 입력 행렬과 합성곱 필터를 혼합함.
기계 학습에서 "합성곱"이라는 용어는 합성곱 연산이나 합성곱층의 약칭으로 종종 쓰임.
합성곱 없이는 기계 학습 알고리즘은 거대한 텐서의 각 셀에 대하여 개별적으로 가중치를 학습해야만 함. 예를 들어 2K x 2K 이미지에 대한 기계 학습 훈련 알고리즘은 4M의 개별 가중치를 찾아야만 함. 합성곱 덕분에 기계 학습 알고리즘은 합성곱 필터의 각 셀에 대해서만 가중치를 찾으면 되며 이를 통해 모델 훈련을 위한 메모리를 극적으로 줄일 수 있음. 합성곱 필터를 적용할 때는 간단하게 셀을 따라 각 셀이 필터에 의해 곱해짐.
합성곱 신경망 convolutional neural network
하나 이상의 계층이 합성곱층인 신경망. 전형적인 합성곱 신경망은 다음과 같은 계층의 조합으로 구성:
- 합성곱층
- 풀링층
- 빽빽한 계층
합성곱 신경망은 이미지 인지와 같은 특정 종류의 문제에 대해서 엄청난 성공을 거둠.
합성곱 연산 convolutional operation
다음과 같은 2단계 수학 연산:
- 합성곱 필터와 입력 행렬의 조각(slice) 간의 요소 단위 곱셈. (입력 행렬의 조각은 합성곱 필터와 동일한 랭크와 형태를 가짐.)
- 결과로 나오는 행렬의 각 값의 덧셈.
예를 들어, 5x5 입력 행렬이 다음과 같음:

그리고 2x2 합성곱 필터는 다음과 같음:

각 합성곱 연산은 입력 행렬의 2x2 조각 각각에 적용됨. 예를 들어 입력 행렬의 왼쪽 위의 2x2 조각에 적용된다고 할 때, 이 조각에 대한 합성곱 연산은 다음과 같음:

합성곱층은 일련의 합성곱 연산으로 구성되며 각 연산은 입력 행렬의 서로 다른 조각에 대해 적용됨.
합성곱 필터 convolutional filter
합성곱 연산의 두 주연 중 하나.(다른 한 주연은 입력 행렬의 조각(slice) 합성곱 필터는 입력 행렬과 랭크는 같지만 형태는 더 작은 행렬임. 예를 들어, 28x28 입력 행렬이 주어진다면, 필터는 28x28 보다는 작은 2차원 행렬이 됨.
사진 조작 분야에서, 합성곱 필터의 각 셀은 보통 1과 0의 일정한 패턴으로 설정됨. 기계 학습에서는 합성곱 필터는 보통 난수로 생성하여 설정한 뒤, 신경망이 이상적인 값으로 훈련함.
합성곱층 convolutional layer
입력 행렬에 대해 합성곱 필터가 적용되는 심층 신경망의 계층. 예를 들어 다음과 같은 합성곱 필터가 있다면:

다음 애니메이션은 5x5 입력 행렬에 대한 9개의 합성곱 연산으로 이루어진 합성곱층을 보여줌. 각 합성곱 연산은 입력 행렬의 서로 다른 3x3 조각(slice)에 적용되는 점에 유의. 결과로 나오는 3x3 행렬(오른쪽)은 9개의 합성곱 연산의 결과로 구성됨:
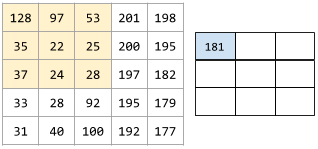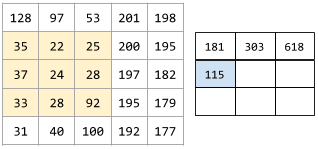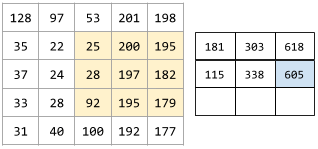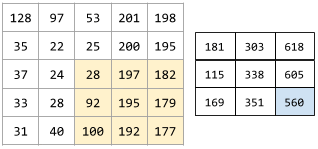
해석성 interpretability
모델의 예측이 쉽게 해석되는 정도. 심층 모델은 종종 해석이 불가능함; 즉, 심층 모델의 서로 다른 층은 해독하기 어려울 수 있음. 대조적으로 선형 회귀 모델과 와이드 모델은 보통 훨씬 해석하기 쉬움.
협업 필터링 collaborative filtering
다른 많은 사용자의 관심사에 기반하여 한 사용자의 관심사를 예측함. 협업 필터링은 추천 시스템에 자주 사용됨.
혼동 행렬 confusion matrix
분류 모델의 예측이 얼마나 잘 맞았는지 요약한 NxN 표; 즉, 레이블과 모델의 분류 간의 상관 관계. 혼동 행렬의 한 축은 모델이 예측한 레이블이며 다른 한 축은 실제의 레이블, N은 범주의 갯수를 의미함. 이진 분류 문제에서는, N=2. 예를 들어, 이진 분류 문제의 혼동 행렬은 다음과 같음:
| 종양 있음 (예측) | 종양 없음 (예측) | |
|---|---|---|
| 종양 있음 (실제) | 18 | 1 |
| 종양 없음 (실제) | 6 | 452 |
앞의 혼동 행렬은 19개 표본이 실제로 종양을 가지고 있었으며, 모델은 18개의 표본이 종양을 가지고 있다고 옳게 분류하였고(18 참 양성), 1개의 표본이 종양을 가지고 있지 않다고 틀리게 분류하였음(1 거짓 음성)을 보여줌. 비슷하게, 458개의 표본이 실제로 종양을 가지고 있지 않았으며, 452개의 표본이 옳게 분류되었고(452 참 음성) 6개의 표본이 틀리게 분류되었음(6 거짓 양성).
다중 범주 혼동 행렬은 오류 패턴을 알아내는 데 도움을 줄 수 있음. 예를 들어, 숫자 손글씨를 알아보도록 훈련된 모델이 4 대신 9로 예측하거나, 7 대신 1로 잘못 예측하는 경향이 있음을 밝혀낼 수 있음. 혼동 행렬은 정밀도와 재현율을 포함해 다양한 성능 메트릭을 계산할 수 있는 충분한 정보를 포함함.
혼잡도 perplexity
모델이 과제를 얼마나 잘 달성했는지에 대한 하나의 척도. 예를 들어, 사용자가 스마트폰 자판에 입력하는 처음 몇 글자를 읽고 가능한 완성 단어 목록을 제안하는 과제에 있어서 혼잡도, P는 사용자가 입력하고자 하는 실제 단어가 목록에 포함되도록 하기 위해 제안해야 하는 추측한 단어의 갯수로 볼 수 있음.
혼잡도는 다음과 같이 크로스엔트로피와 관련됨:
확률적 기울기 하강 stochastic gradient descent (SGD)
배치 크기가 1인 기울기 하강 알고리즘. 즉, SGD는 각 단계마다 기울기에 대한 평가를 계산하기 위해 데이터셋으로부터 균일하게 무작위로 선택된 하나의 보기에 의존.
활성화 함수 activation function
앞 계층으로부터 받은 모든 입력에 대해 가중치를 반영하여 더한 다음, 출력 값을 생성하여(일반적으로 비선형) 다음 계층으로 넘겨주는 함수. 예: ReLU 혹은 시그모이드
회귀 모델 regression model
출력이 연속 값(보통 실수)인 모델의 한 유형. 출력이 "원추리" 혹은 "참나리"와 같이 이산 값인 분류 모델과 비교해 볼 것.
회전 불변성 rotational invariance
이미지 분류 문제에서 이미지의 방향이 바뀌어도 이미지를 성공적을 분류해 내는 알고리즘의 능력. 예를 들어, 테니스 라켓이 위로 향하고 있거나 옆으로 누워 있거나 아래로 향하고 있는 경우에도 알고리즘이 인지해 낼 수 있음을 의미함. 회전 불변성이 항상 바람직하지 않음에 유의할 것; 예를 들어, 위 아래가 뒤집어진 숫자 9는 9로 분류되어서는 안 됨.
후보 샘플링 candidate sampling
소프트맥스 등을 사용하여 양성 레이블은 전체 표본에 대해서, 음성 레이블은 무작위로 선택된 표본에 대해서만 확률을 계산하는 훈련 중 최적화. 예를 들어, 비글, 개로 레이블된 보기가 있을 때, 후보 샘플링은 다른 범주(고양이, 막대 사탕, 펜스 등)의 무작위 부분 세트와 비글, 개 범주 출력에 대한 예측된 확률 및 관련된 손실 항을 계산함. 양성 범주가 항상 제대로 된 양성 강화가 이뤄지고 있는 한, 음성 범주는 더 적은 음성 강화로도 학습이 가능하다는 아이디어에서 출발하였으며, 경험적으로 실제로 관찰됨. 후보 샘플링의 동기는, 음성 보기에 대한 예측을 계산하지 않는 쪽이 계산 효율이 높다는 점에 있음.
훈련 training
모델을 이루는 이상적인 파라미터를 알아내는 과정.
훈련 세트 training set
모델 훈련에 쓰이는 데이터셋의 부분 세트.
휴리스틱 heuristic
문제에 최적화된 것을 아니지만, 진전을 이루거나 학습을 진행하는 데에는 충분한 경험적인 해답.
희박성 sparsity
벡터 혹은 행렬 내에서 0으로(혹은 null로) 설정된 요소의 숫자를 벡터 혹은 행렬 전체 엔트리의 숫자로 나눈 값. 예를 들어, 98개의 셀이 0을 포함하는 10x10 행렬의 희박성을 계산하면 다음과 같음:
특징 희박성은 특징 벡터의 희박성을 일컬음; 모델 희박성은 모델 가중치의 희박성을 일컬음.
희박한 특징 sparse feature
대부분의 값이 0이거나 비어있는 특징 벡터. 예를 들어, 하나만 값이 1이고 나머지 백만개의 값은 0인 벡터는 희박함. 다른 예로는, 조회 쿼리의 단어는 주어진 언어에 많은 단어가 있음에도 몇 개의 단어만이 쿼리에 나타났을 것이므로 희박한 특징이 될 수 있음.
빽빽한 특징과 대조해 볼 것.
희박한 표현 sparse representation
0이 아닌 요소만 저장하는 텐서 표현.
예를 들어, 영어는 약 백만개의 단어로 구성되어 있는데, 영문장 하나에 사용된 단어를 세는 표현은 두 가지를 고려할 수 있음:
- 이 문장의 빽빽한 표현은 백만개의 셀 모두를 정수로 설정하고 그 대부분을 0으로, 몇 개에는 작은 정수를 둠.
- 이 문장의 희박한 표현은 이 문장에 실제 사용된 단어를 상징하는 셀만을 저장함. 따라서, 문장이 단 20개의 각기 다른 단어만을 포함한다면, 희박한 표현은 단 20개 셀에 정수를 저장함.
예를 들어, "Dogs wag tails."라는 문장을 표현하는 경우, 다음 표가 보여주듯이 빽빽한 표현은 백만개의 셀을 사용함; 희박한 표현은 단 3개의 셀만 사용함:
빽빽한 표현
| 셀 번호 | 단어 | 등장 빈도 |
|---|---|---|
| 0 | a | 0 |
| 1 | aardvark | 0 |
| 2 | aargh | 0 |
| 3 | aarti | 0 |
| … 140,391개의 0번 등장하는 단어들 | ||
| 140395 | dogs | 1 |
| … 633,062개의 0번 등장하는 단어들 | ||
| 773458 | tails | 1 |
| … 189,136개의 0번 등장하는 단어들 | ||
| 962594 | wag | 1 |
| …수많은 0번 등장하는 단어들 |
희박한 표현
| 셀 번호 | 단어 | 등장 빈도 |
|---|---|---|
| 140395 | dogs | 1 |
| 773458 | tails | 1 |
| 962594 | wag | 1 |
A/B 테스팅 A/B testing
두 개(혹은 그 이상)의 기법을 비교하는 통계적 방법으로, 일반적으로 기존안 하나에 신규안을 대조시킴. A/B 테스팅은 어떤 기법의 성능이 더 우수한지 밝혀내는 것 뿐만 아니라 이러한 차이가 통계적으로 유의미한지를 이해하는 것 또한 목표로 함. A/B 테스팅은 보통 단 두 개의 기법에 대해 하나의 척도를 사용하는 것만을 고려하지만, 유한한 갯수의 여러 기법과 척도를 적용할 수도 있음.
AdaGrad
정교한 기울기 하강 알고리즘으로 각각의 파라미터에 독립적인 학습률을 효과적으로 부여하여 파라미터 별로 기울기의 범위를 조정함. 완전한 해설은 이 논문을 참조.
AUC (Area under the ROC Curve)
가능한 모든 분류 임계값을 고려한 평가 메트릭.
ROC 커브 아래의 면적은 무작위로 선택된 음성 보기가 분류기에 의해 양성으로 예측되는 것보다 무작위로 선택된 양성 보기가 실제로 양성으로 예측되는 것을 확신하는 확률임.
binning
버킷팅을 참조.
epoch
각각의 보기를 다 한번씩 보도록 전체 데이터셋을 완전히 한 번 훈련함. 따라서 N이 보기의 총 갯수라 할 때, epoch는 N/배치 크기 훈련 반복 수행.
Estimator
텐서플로우 그래프를 쌓고 세션을 돌리는 논리를 캡슐화하는 tf.Estimator 클래스의 인스턴스. (여기에 기술된 것처럼)Estimator를 직접 만들 수도 있고 사전에 만들어진 Estimator를 인스턴스화 할 수도 있음.
Keras
인기 있는 파이썬 기계학습 API. Keras는 여러 심층 학습 프레임워크 상에서 실행할 수 있으며 그 중 텐서플로우에서는 tf.keras 형태로 사용할 수 있음.
Kernel Support Vector Machines (KSVMs)
입력 데이터 벡터를 고차원 공간에 대응시켜 양성과 음성 범주 간의 차이를 최대화하고자 하는 분류 알고리즘. 예를 들어, 백개의 특징으로 이루어진 입력 데이터셋을 가진 분류 문제를 고려해 보면, 양성과 음성 범주 간의 차이를 최대화하려면 KSVMs는 내부적으로 이 특징들을 백만차원의 공간에 대응시켜야 함. KSVMs은 경첩 손실이라는 손실 함수를 사용함.
k-means
비지도 학습에서 보기를 그룹화하는 인기있는 군집화 알고리즘. k-means 알고리즘은 기본적으로 다음과 같은 작업을 함:
- 반복적으로 최고의 k개의 중심점을 결정함.
- 가장 가까운 중심점에 각 보기를 할당함. 같은 중심점에 가장 가까운 이 보기들은 같은 그룹에 속함.
k-means 알고리즘은 각 보기에서 가장 가까운 중심점까지 거리의 제곱의 누적값을 최소화하는 중심점을 고름.
예를 들어, 개의 체장에 대해 체고를 다음과 같이 플롯한다면:

k=3일 때, k-means 알고리즘은 세 개의 중심점을 결정함. 각 보기는 각각 가장 가까운 중심점에 할당되어 세 개의 그룹으로 산출됨:

애견용 스웨터 제조업체가 소형견, 중형견, 대형견에 이상적인 스웨터 크기를 알고 싶은 경우, 세 개의 중심점은 각 군집에 속하는 개의 평균 체장과 체고을 알려줌. 따라서, 제조업체는 이 세 개의 중심점에 맞춰 스웨커 크기를 결정할 수 있음. 군집의 중심점은 군집 내의 보기가 아님에 유의.
앞의 예시는 단 두 개의 특징(체장과 체고)을 가지는 보기에 대한 k-means 임. k-means는 많은 특징을 가지는 보기도 그룹화할 수 있음에 유의.
k-median
k-means와 밀접하게 관계 있는 군집화 알고리즘. 두 알고리즘 사이의 실제적인 차이점은 다음과 같음:
- k-means은 각 보기로부터 가장 가까운 후보 중심점 간 거리의 제곱의 합을 최소화 하는 중심점을 선택.
- k-median은 각 보기로부터 가장 가까운 후보 중심점 간 거리의 합을 최소화 하는 중심점을 선택.
거리의 정의 또한 다음과 같이 다름에 유의:
- k-means은 중심점부터 보기까지의 Euclidean distance를 사용.(2차원에서 Euclidean distance 는 빗변을 계산하는 피타고라스 정리를 사용) 예를 들어, (2,2)와 (5,-2) 사이의 k-means 거리는 다음과 같음:
- k-median은 중심점부터 보기까지의 Manhattan distance를 사용하며 각 차원의 절대 차이의 합계임. 예를 들어, (2,2)와 (5,-2) 사이의 k-median 거리는 다음과 같음:
logits
분류 모델이 생성한 원본(표준화 되지 않은) 예측의 벡터로, 통상적으로 표준화 함수로 전달됨. 모델이 다중 범주 분류 문제을 풀고 있다면, logits은 보통 소프트맥스 함수의 입력이 됨. 그러면 소프트맥스 함수는 가능한 범주 별로 (표준화된)확률값의 벡터를 생성함.
추가적으로, logits은 때때로 시그모이드 함수의 요소단위 역수를 일컫기도 함. 좀 더 상세한 정보는 tf.nn.sigmoid_cross_entropy_with_logits을 참조.
log-odds
어떤 사건에 대한 odds의 대수.
사건이 이진 확률일 때 odds는 성공 확률 (p)를 실패 확률 (1-p)로 나눈 비율을 일컬음. 예를 들어 주어진 사건의 성공 확률이 90%, 실패 확률이 10%라 하면, odds는 다음과 같이 계산됨:
log-odds는 단순히 odd의 대수. 관습적으로 "대수"는 자연 대수를 일컬으나, 실제로 대수는 1보다 큰 어떠한 밑수도 가능함. 위 보기에 대한 관습에 따른 log-odds는 다음과 같음:
log-odds는 시그모이드 함수의 역수임.
L1 손실 L1 loss
레이블의 실제 값과 모델이 예측한 값의 차이의 절대값에 기반한 손실 함수. L1 손실은 L2 손실보다 특이값에 덜 민감함.
L1 정규화 L1 regularization
가중치의 절대값의 합에 비례하여 벌점의 가중치를 주는 정규화의 한 유형. 희박한 특징에 의존하는 모델에는, L1 정규화가 관련이 없거나 관련도가 낮은 특징의 가중치를 정확히 0으로 만들어 모델에서 해당 특징을 제거할 수 있도록 도움을 줌. L2 정규화와 대조해볼 것.
L2 손실 L2 loss
제곱 손실을 참조.
L2 정규화 L2 regularization
가중치의 "제곱의" 합에 비례하여 벌점의 가중치를 주는 정규화의 한 유형. L2 정규화는 특이값(큰 양수나 음수)의 가중치를 0에 가깝지만 딱 0은 아닌 값으로 만드는 데에 도움을 줌(L1 정규화와 대조해 볼 것). L2 정규화는 항상 선형 모델의 일반화를 개선함.
ML
기계 학습의 약자.
NaN 함정 NaN trap
모델 내의 숫자 하나가 훈련 중에 NaN이 되버린 상황. 모델 내의 많은 혹은 모든 숫자를 결국에는 NaN으로 만들어 버림.
NaN은 "숫자 아님 Not a Number"의 약자임.
numpy
파이썬에서 효율적인 배열 연산을 제공하는 오픈 소스 수학 라이브러리. pandas는 NumPy 기반으로 만들어짐.
pandas
열-기반 데이터 분석 API. 텐서플로우를 포함한 많은 ML 프레임워크가 pandas 데이터 구조를 입력으로 지원함. pandas 공식 문서를 참조.
Parameter Server (PS)
분산된 설정에서 모델의 파라미터를 지속적으로 기록하는 작업.
Rectified Linear Unit (ReLU)
다음과 같은 규칙을 가지는 활성화 함수:
- 입력이 음수이거나 0이면, 출력은 0.
- 입력이 양수이면, 출력은 입력과 같음.
ROC 커브 ROC (receiver operating characteristic) Curve
서로 다른 분류 임계값에 대한 참 양성률 vs. 거짓 양성률의 커브. AUC를 함께 참조할 것.
SavedModel
텐서플로우 모델의 저장과 복구에 추천되는 포맷. SavedModel은 언어중립적이고, 복구가능 시리얼화 포맷으로 좀 더 고수준 시스템과 도구가 텐서플로우 모델을 만들고 사용하고 변환할 수 있도록 해줌.
상세 정보는 TensorFlow Programmer's Guide의 Saving and Restoring 참고.
Saver
모델 체크포인트 저장을 담당하는 텐서플로우 객체.
scikit-learn
인기 있는 오픈 소스 ML 플랫폼. www.scikit-learn.org를 참조.
stride
합성곱 연산 혹은 풀링에서 입력 조각과 다음 입력 조각 사이의 각 차원에서의 차이. 예를 들어, 다음 애니메이션은 합성곱 연산동안 (1, 1) stride를 보여줌. 따라서 다음 입력 조각은 앞 입력 조각의 한 칸 오른쪽에서 시작함. 연산이 오른쪽 가장자리까지 도달하면 다음 조각은 한 칸 아래의 왼쪽 가장자리에서 시작함:
앞의 보기는 2차원 stride의 예시임. 입력 행렬이 3차원인 경우, stride 역시 3차원이 됨.
Tensor Processing Unit (TPU)
텐서플로우 프로그램의 성능에 최적화된 주문형 반도체(ASIC, application-specific integrated circuit).
tf.Example
기계 학습 훈련 혹은 추론에 쓰이는 입력 데이터의 기술을 위한 표준 프로토콜 버퍼.
3차 추가: 2018년 04월 26일 (현재)
2차 추가: 2018년 01월 02일
1차 추가: 2017년 12월 02일
최초 개시: 2017년 11월 16일
번역: 김정묵
감수: 신정규 박종현 김준기 조만석
라이선스 안내
"우리말 기계학습 용어집" 강의는 Google의 Machine Learning Glossary를 Creative Commons 3.0 Attribution License 하에 우리말로 번역한 것입니다. "우리말 기계학습 용어집"은 Creative Commons 3.0 Attribution License를 따릅니다.
Notice
Portions of this page are modifications based on work created and shared by Google and used according to terms described in the Creative Commons 3.0 Attribution License.
토론이 없습니다