Keras 함수형 API로 시작하기
Keras의 함수형 API(functional API)는 다중 출력 모델, 방향성 비순환 그래프(directed acyclic graph), 공유 계층(shared layer)를 가지는 모델 등과 같은 복잡한 모델을 정의하는 방법입니다.
이 가이드는 사용자가 이미 Sequential 모델에 익숙하다고 가정합니다.
간단한 것부터 시작해 봅시다.
첫 번째 예제: 연결 밀도가 높은 네트워크 (densely-connected network)
이 네트워크를 구현할 때 Sequential 모델을 사용하는 것이 더 좋지만, 아주 간단한 것부터 시작해보는 것이 이해에 도움이 됩니다.
- 계층 인스턴스는 (텐서에서) 호출할 수 있으며 텐서를 반환합니다.
- 입력 텐서와 출력 텐서를 사용하여
Model을 정의 할 수 있습니다. - 이렇게 만든 모델은 Keras의
Sequential모델과 마찬가지로 훈련에 사용할 수 있습니다.
Notice
CodeOnWeb에서는 따로 파이썬을 설치하지 않더라도 코드박스 아래의 실행 버튼을 클릭하여 바로 파이썬 코드를 실행해볼 수 있습니다. TensorFlow, Theano와 같은 백엔드 코드도 마찬가지로 설치 없이 실행 버튼만 눌러 실행할 수 있습니다. 'Keras 연습하기' 과정에서는 실행 결과까지 출력하는 예제 코드에 대해서만 실행하여 결과를 확인할 수 있도록 하였습니다.
계층과 마찬가지로, 모든 모델은 호출 가능합니다
함수형 API를 사용하면 훈련된 모델을 쉽게 재사용할 수 있습니다. 모든 모델은 텐서에서 호출하여 마치 계층처럼 취급할 수 있습니다. 모델을 호출하면 모델의 아키텍처를 재사용할 뿐만 아니라 가중치도 재사용한다는 점에 주목하십시오.
예를 들어, 일련의 입력을 처리 할 수있는 모델을 신속하게 작성할 수 있습니다. 한 줄만 바꾸면 이미지 분류 모델을 비디오 분류 모델로 바꿀 수 있습니다.
다중 입력 및 다중 출력 모델
다중 입력과 출력을 가지는 모델은 함수형 API를 이용하는 좋은 사례입니다. 함수형 API를 사용하면 많은 수의 서로 얽힌 데이터 스트림을 쉽게 조작 할 수 있습니다.
다음과 같은 모델을 고려해 봅시다. 우리는 트위터에서 뉴스 헤드라인이 얼마나 많은 리트윗과 좋아요를 받을지 예측하고자 합니다. 모델의 주된 입력은 헤드라인을 구성하는 단어가 되겠지만, 좀더 좋은 결과를 위해 헤드라인이 작성된 시간 등과 같은 데이터도 보조 입력으로 줄 수 있습니다. 이 모델은 두 종류의 손실함수(loss functions)를 통해 관리됩니다. 모델 초기에 주된 손실함수를 두는 것은 딥모델을 위한 좋은 정규화 작업입니다.
우리 모델은 다음과 같이 생겼습니다.
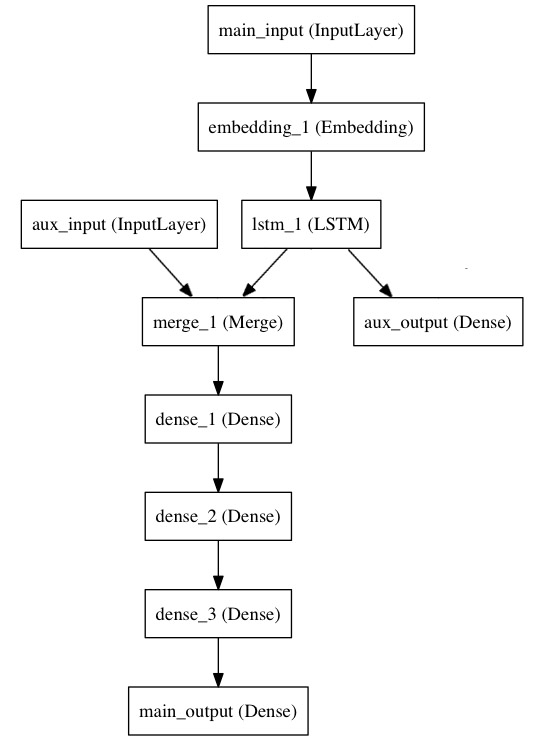
이 모델을 함수형 API로 구현해보겠습니다.
주 입력 계층은 헤드라인을 받아들이는데, 이때 헤드라인은 연속된 정수(각 정수는 단어를 인코딩한 것) 형태가 됩니다(문자로 된 헤드라인을 그대로 처리할 수 없으므로 숫자로 바꾸어 입력합니다). 정수는 1에서 10,000 사이이며 (10,000단어로 된 단어집(vocabulary)) 연속된 정수의 길이는 100단어가 됩니다.
여기서 보조 손실함수를 추가하여 모델에서 주 손실이 훨씬 크더라도 LSTM과 임베딩(embedding) 계층이 매끄럽게 훈련되도록 합니다.
이 시점에서 우리는 보조 입력 데이터를 LSTM 출력과 상호연결(concatenate)하여 모델에 집어넣습니다:
다음과 같이 모델이 두 개의 입력과 두 개의 출력을 가지도록 정의합니다.
모델을 컴파일하면서 0.2의 가중치를 보조 손실에 할당합니다. 각 출력에 서로 다른 loss_weights 또는 loss를 지정하려면 리스트나 딕셔너리를 사용할 수 있습니다. 여기서는 loss 인수를 통해 하나의 손실을 전달하므로, 모든 출력에서 같은 손실이 사용됩니다.
입력 배열과 목표 배열의 리스트를 전달하여 모델의 훈련을 진행합니다:
("name" 인수를 이용해) 입력과 출력에 이름을 붙였으므로 우리는 다음과 같이 모델을 컴파일할 수도 있습니다:
공유 계층
공유 계층은 함수형 API를 적용할 수 있는 또 다른 좋은 모델입니다. 공유 계층에 관해 살펴보겠습니다.
트위터의 데이터셋을 생각해 봅시다. 우리는 두 개의 트윗이 같은 사람이 작성한 것인지 아닌지 알 수 있는 모델을 만들려고 합니다. (예를 들어, 트윗 간의 유사도를 통해 사용자를 비교해볼 수 있습니다)
생각해 볼 수 있는 한 가지 방법은, 두 트윗을 두 개의 벡터로 인코딩하고 벡터를 상호연결(concatenate)한 후 로지스틱 회귀에 넣어 두 트윗이 같은 사용자에게서 나왔을 확률을 출력하는 모델을 만드는 것입니다. 그리고 이 모델을 긍정적인 트윗 쌍과 부정적인 트윗 쌍 데이터를 이용해서 훈련시킵니다.
문제에 대칭성이 있으므로, 첫 번째 트윗을 인코딩하는 방법(가중치 등)은 두 번째 트윗을 인코딩하는 데 다시 사용해야 합니다. 여기서는 공유 LSTM 계층을 사용하여 트윗을 인코딩해보겠습니다.
함수형 API로 구현해봅시다. (140, 256) 모양의 이진 행렬을 이용해서 트윗을 입력하도록 합니다. (여기서 256차원 벡터의 각 차원은 256개의 자주 사용되는 알파벳 문자의 존재/부재 정보를 인코딩합니다).
다양한 입력에 대해 계층을 공유하려면 계층을 한 번만 인스턴스화한 다음 이를 여러 입력에 대해 호출하면 됩니다:
잠시 멈추고 공유 계층의 출력 또는 출력 모양을 자세히 한 번 살펴봅시다.
계층 "노드"의 개념
어떤 입력에 한 계층을 적용할 때마다 새로운 텐서(계층의 출력)가 만들어지고, 계층에는 "노드"가 추가되어 입력 텐서와 출력 텐서를 연결하게 됩니다. 같은 계층을 여러 번 호출하면 해당 계층은 0, 1, 2… 로 인덱싱 된 여러 노드를 가집니다.
예전 Keras 버전에서 계층 인트턴스의 출력 텐서나 출력 형태를 얻으려면 layer.get_output()이나 layer.output_shape를 이용해야 했습니다. 여전히 이렇게 할 수 있지만(단, get_output ()가 output이라는 속성(property)으로 바뀌었습니다), 계층이 여러 입력에 연결된 경우에는 어떻게 해야 할까요?
한 계층이 하나의 입력에만 연결되어 있다면 헷갈릴 것이 없으며, .output은 해당 계층의 출력 하나를 반환합니다.
계층이 여러 개의 입력을 가지고 있다면 이야기는 달라집니다:
네, 그러면 다음과 같이 해봅시다:
충분히 간단합니다, 그렇죠?
input_shape 및 output_shape 속성도 마찬가지입니다. 계층에 하나의 노드만 있거나 모든 노드가 같은 입출력 형태를 가진다면, "계층 출력/입력 형태"가 잘 정의되므로 layer.output_shape/layer.input_shape에 의해 하나의 결과가 반환됩니다. 그러나 예를 들어 (3, 32, 32) 모양을 가지는 입력과 (3, 64, 64) 모양을 가지는 입력에 같은 Conv2D 계층을 적용하면, 계층은 여러 입출력 형태를 가지게 되어 노드의 인덱스를 지정해야만 해당 형태를 얻을 수 있습니다.
더 많은 예제
역시 예제 코드를 통해 시작하는 것이 최선입니다. 몇 가지만 소개합니다.
인셉션(Inception) 모듈
인셉션 아키텍쳐에 대해 궁금하신 분은 Going Deeper with Convolutions를 참고하세요.
Residual connection on a convolution layer
Residual network에 대해 궁금하신 분은 Deep Residual Learning for Image Recognition를 참고하세요.
공유 비전 모델
이 모델은 같은 이미지 처리 모듈을 두 입력에 재사용해서 두 MNIST 숫자가 같은지 다른지 분류합니다.
시각적 질문 응답 모델(Visual question answering model)
이 모델은 사진에 대한 자연어로 된 질문을 받아 올바른 한 단어 응답을 선택할 수 있습니다.
질문과 이미지를 각각 벡터로 인코딩하고, 둘을 연결하여 로지스틱 정답 가능성이 있는 단어집(vocabulary)에 대한 로지스틱 회귀 분석을 수행합니다.
영상 질문 응답 모델
이미지에 대한 질문/응답 모델을 훈련시켰으니, 이를 영상에 대한 질문/응답 모델로 재빠르게 바꿀 수 있습니다. 적절한 훈련을 통해 짧은 동영상(예를 들어, 사람의 움직임을 담은 100 프레임 영상)을 보여주고, 그 영상에 대한 자연어 형태의 질문(예: '소년은 어떤 스포츠를 하고 있나요?'> '축구')을 할 수 있습니다.
이 문서는 Keras의 Guide to the Functional API을 번역한 것입니다.
최종 수정일: 2017년 8월 17일.
토론이 없습니다